![]() Lobbyist Lookup is a Go program that downloads, parses, and allows users to search over 310,000 US Congressional Lobbyist Disclosure filings.
Lobbyist Lookup is a Go program that downloads, parses, and allows users to search over 310,000 US Congressional Lobbyist Disclosure filings.
Over the summer this year, I participated in the National Day of Civic Hacking (NDOCH) organized by the Northern Virginia Code for America Brigade and sponsored by the National Science Foundation (NSF). At NDOCH, I teamed up with Leandra Tejedor and Sherry Wang to create Lobbyist Lookup to solve the NSF’s Ethics Challenge.
What is the NSF Ethics Challenge?
- Per 5 C.F.R. Part 2635, executive branch employees may not accept gifts from lobbyists. Other branches of government have their separate rules regarding gift receiving. The Office of Government Ethics is proposing extending the lobbyist gift ban to cover all federal employees.
- A Presidential memorandum dated June 18, 2010 directed Executive agencies, not to appoint or re-appoint Federally registered lobbyists to advisory committees, review panels, or other similar groups.
- Currently looking up lobbying status involves searching House.gov and Senate.gov lobbyist disclosure databases which are completely separate, have dissimilar interfaces, and different formats. There is no feedback when typing a search term so a misspelling of Dylan vs Dillon could have legal consequences.
- Federal employees need a way to lookup the lobbying status of an individual or organization to quickly and accurately determine gift giving eligibility.
NDOCH had many other programming challenges and activities to do. Many of these challenges had APIs and sponsor governmental organizations readily providing data. Our two houses of Congress, the House and Senate, had web interfaces which citizens use to search through filings with and bulk filing download pages.
Sections:
- The NSF Ethics Challenge
- Getting House data
- Getting Senate data
- Data unification
- JS web lookup goodness
- Performance Issues and Approaches
- Miscellaneous
House
House.gov download button
Our team’s first objective was somehow parse the filing data so that we could search it. For the House data, we manually downloaded and unarchived the filings. Each filing had its own XML file with a structure similar to
- Filing
- Organization
- Client
- Lobbyists
- John Doe
- Steve Ha
I choose to use Go as the language to parse and search the filings. Why not? (Actually there are a lot of reasons why not, but we can go over that later)
I defined a HouseFiling and HouseLobbyist structure
The xml: portion after each property of the struct indicates the source element in the XML file to get data from. We have an array for the Lobbyist property because the XML file provides multiple Lobbyist elements each with presumably different lobbyists. Use encoding/xml in Go to unmarshal the XML into the HouseFiling struct.
oneFiling := HouseFiling{}<br />
xml.Unmarshal(XMLDATA, &oneFiling)
Now that all the filings were parsed into an array of HouseFiling structs, we started a server in a Goroutine to receive queries and had it loop the array to find matching filings. It acted as an API that clients could interact with. Leandra and Sherry worked on a Python parser for the Senate data and created basic web interface for queries. That was all we got done with in about 6 hours and we got 1st for the hackathon. Prize was dinner with Dr. Cora B. Marrett, Deputy Director, NSF.
Anyways, we had gotten the House and Senate data parsed but only the House data was searchable. We had also taken the easy route by manually downloading the data and providing a source directory for our Go and Python programs. We kept working on the program to make it usable.
Hm, so we sort of want to automate the download of data from the House. That should be easy, right?
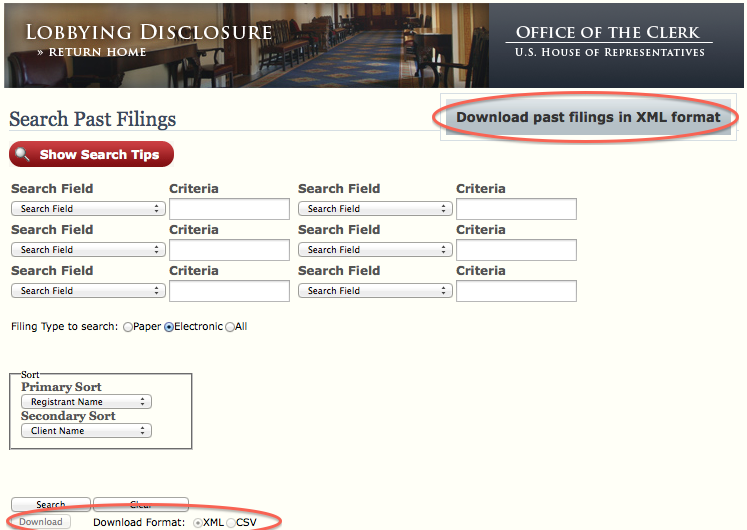
House.gov Lobbyist Disclosure Filing Search
First we look at the lower left button. It says matter of fact Download and lets us choose a format! Wow, XML and CSV are nice options I think. Maybe we can create a custom form that interacts with the server and then we download the results in XML?

Result of trying to download a search with many matches
Ha ha, nice one. Guess the House doesn’t want to show too many results, but they DO let us download all filings in a ZIP archive. Each archive definitely contains more than 2000 records… So…yeah. The button to do so is circled in the previous screenshot.
House.gov download form
When following the link, we get to a page that consist of an HTML form with a drop down selection of quarterly archives and a download button. This page’s URL is http://disclosures.house.gov/ld/LDDownload.aspx?KeepThis=true&. Keeping it in mind, it will come handy later.
I thought that it would a simple matter to deduce the format of the file URLs and getting the filings by iterating though /201X_1stQuarter.zip to /201X_4thQuarter.zip. When receiving the archives from the server, there should be an originating path that the file is coming from.
Download URL in Chrome
Wait, what the?! It’s coming from the exact same url as the form page with no file in the path! Looking at the form code for details shows us this snippet:
Hm… this form uses POST to send the form contents to itself.
No problem right? We can predict the file names from the drop down, submit a POST request, and read the reply to get the file.
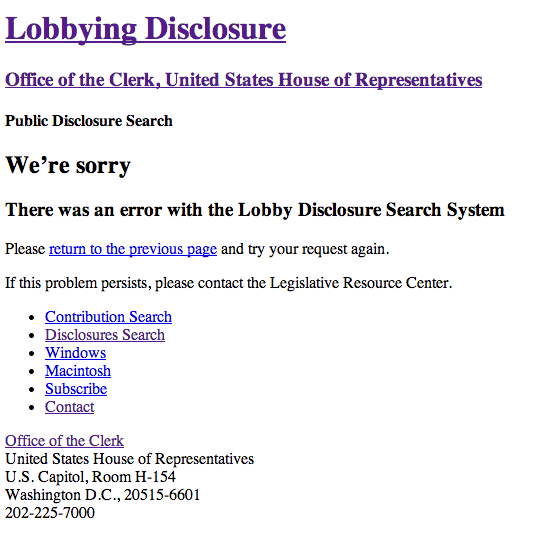
Oh no! That didn’t work like I thought it would.
Our browser is not sending something that the server needs. What could it be?
The form on the page includes hidden elements __VIEWSTATE and __EVENTVALIDATION.
What are these? They are used by ASP to prevent Cross-Site Request Forgery (CSRF). Can we still get at the public data?
The hidden input items work by ensuring that the user browser has actually visited the ASP page and sent an authentic request originating from the user. It assigns each visitor a unique __VIEWSTATE and __EVENTVALIDATION and verifying them upon receipt of sent request. We have not been sending the correct __VIEWSTATE or __EVENTVALIDATION — or any data besides our filenames in the POST requests so the server believes a CSRF is being attempted.
We could grab __VIEWSTATE and __EVENTVALIDATION elements from the form and then submit those along with our POST request for the files. There is also a StackOverflow post on this issue.
I used the code.google.com/p/go.net/html Go library to assist with parsing the HTML page into elements and extracting the __VIEWSTATE and __EVENTVALIDATION input element values. Code for this can be found in <a href="https://github.com/ansonl/lobbyist-lookup/blob/master/houseRetrieve.go">houseRetrieve.go</a> in the scrape() function.
The filename parameter includes the updated timestamp so code.google.com/p/go.net/html assisted in scraping those values. I put all the filenames in a slice and requested the files referenced in the last 6 elements of the slice in order to get filings from the past six quarters. After some more testing and failures I found selFilesXML and btnDownloadXML POST parameters are required as well. I have included a table of parameters and explanations in the README.
Whew, that was quite a bit. Take a break, check out the code.
Let’s take a gander at the Senate data.
Senate
Unlike the House the Senate actually has a download page with a link for each filing.
Senate download page
http://soprweb.senate.gov/downloads/2014_1.zip
- http://soprweb.senate.gov/downloads/2014_2.zip*
- http://soprweb.senate.gov/downloads/2014_3.zip*
…
Each quarterly archive has a static URL. This may be our lucky break! Simply iterate through a list of filename and read the responses to our GET requests. Pass the data to xml.Unmarshal and …
xml: Invalid character on line 1 expected
Line 1 of each downloaded XML file is<!--?xml version='1.0' encoding='UTF-16'?-->
It looks and is like valid XML. It also kills many breeds of XML readers due to its 3 MB size. It is also in UTF-16 when Go expects UTF-8.
Trying to convert UTF-16 to UTF-8 from scratch went badly so instead I found the code.google.com/p/go-charset/charset Go library which allowed me to convert formats in a few lines of code.
Now with a UTF-8 byte slice we can unmarshal the data into our defined structs without any issues.
Data unification
I now have two arrays of filings from each house of Congress in different types of structures. To unify them I created a common structure and looped through both arrays, assigning the common structure’s properties the relevant data from the respective house-specific structure.
For some parts of the data such as the lobbyist name, you may notice that the Senate XML files only provide names in a string in format of
DOE, JOHN A
To separate the names, we use Go strings like so
firstName = senateLobbyist.LobbyistName[strings.Index(senateLobbyist.LobbyistName, ",")+1:]<br />
lastName = senateLobbyist.LobbyistName[:strings.Index(senateLobbyist.LobbyistName, ",")]
Find position of first comma in the string. Get portions of string (byte slice) from both sides.
The code for this may be found in <a href="https://github.com/ansonl/lobbyist-lookup/blob/master/combine.go">combine.go</a>. When the program receives a client request, it simply loops through the massive array of 310,000 records looking for matches. All code for this project can be viewed on GitHub.
JS Web lookup
Leandra and I created a Lobbyist Lookup website that may be used here.
The code for the web lookup is available in the gh-pages branch on GitHub.
Most of the logic for the page is written from scratch in Javascript. I’ve attempted to separate them into files aptly named form, filing, and table.
form includes the JQuery submit handler and element animations. It calls functions in filing and table.
filing defines Filing objects for sorting purposes and attempts to clean up received filings by removing blank data and aggressively eliminating lobbyist and filings duplicates.
table creates an HTML table which displays the cleaned up data.
The web lookup page uses JQuery UI’s autocomplete widget which queries the Go app for potential matches and displays possible matches to the user. JQuery made autocomplete an easy drop in.
Implementing autocomplete led to some interesting insights on record fragmentation.
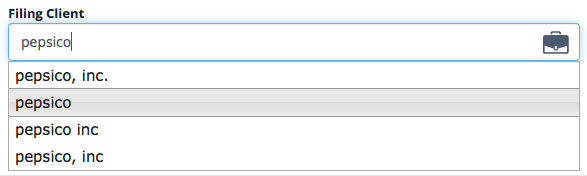
Pepsico autocompleted
As seen above, Pepsico has many possible spellings.

Surname metadata
Surnames can also contain some interesting data such as effective date, occupation, and termination status.
Performance Issues and Approaches
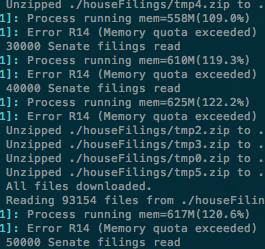
Heroku memory warnings
After adding in the Senate data, we began encountering performance issues. Our Heroku instance began sputtering to a halt at >600 MB memory usage due to throttling on Heroku’s side. AWS free tier instances wouldn’t even make it past parsing all the data, an instance would simply run out of memory.
The Go program would parse filings from each house of Congress into an array of structures unique to that house. When parsing was done we would then pass the two different structures to another function that converted the unique structures into a generic structure that the web server could search through.
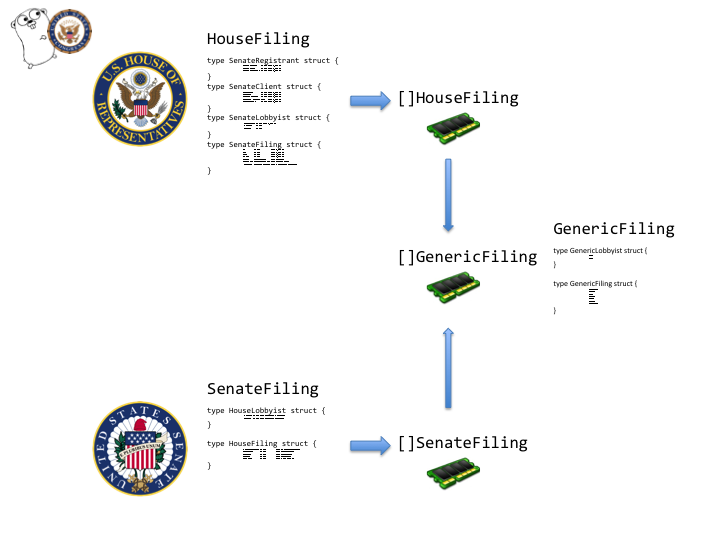
Combine
With only the House data, the Go app took up 512 MB memory on Heroku and ran fine. What could be causing this extra memory usage and resulting performance deterioration besides an extra 200,000 records? The Go app would parse the two houses of congress in Goroutines, Go’s version of threads. That means that both houses could be parsed at the same time and the program would be maintaining separate arrays for each house. I had also passed the arrays by value to the combining function which would require two copies of each array in memory.
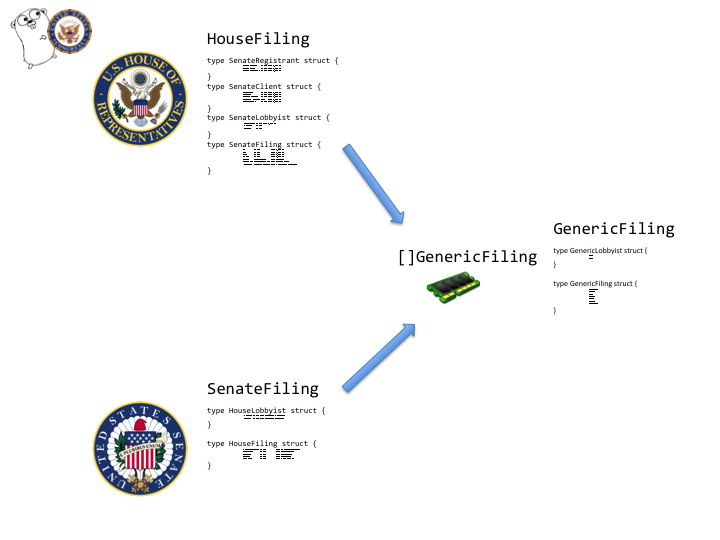
Immediate Conversion
I changed the program to convert each filing into the generic filing structure as soon as it had been parsed rather than wait for the complete parsing of all filings from a house. Since the array of generic filings was being modified from different Goroutines, I used sync.Mutex to avoid problems. The array of generic filings was also changed to be passed by reference so it would not be copied in the combining function.
Even though the end result of both approaches towards parsing and combining is a massive array of filings, the result of the second approach was a more lightweight Go program that used around 540MB memory. It was somewhat more responsive on a 1X Heroku dyno. AWS micro instance still couldn’t handle the heat. This is still a work in progress.
Miscellaneous
You can use Lobbyist Lookup to lookup lobbyists for legal reasons such as gift giving and appointments. It currently allows you to search filings by surname, organization, or client.
Organization vs Client
| Organization | Registering entity. This may be a lobbying firm hired by a client. |
| Client | The entity actually behind the filing. This may be a company (← client) hiring the lobbying firm (← organization). |
You can also use Lobbyist Lookup to discover the lobbying activities of companies of interest for transparency. The API is free for all to modify and use. Download the sample app for iOS that lets you lookup lobbyists natively. The parsed filings contain other information such as income and contributions which you can easily modify to view.
